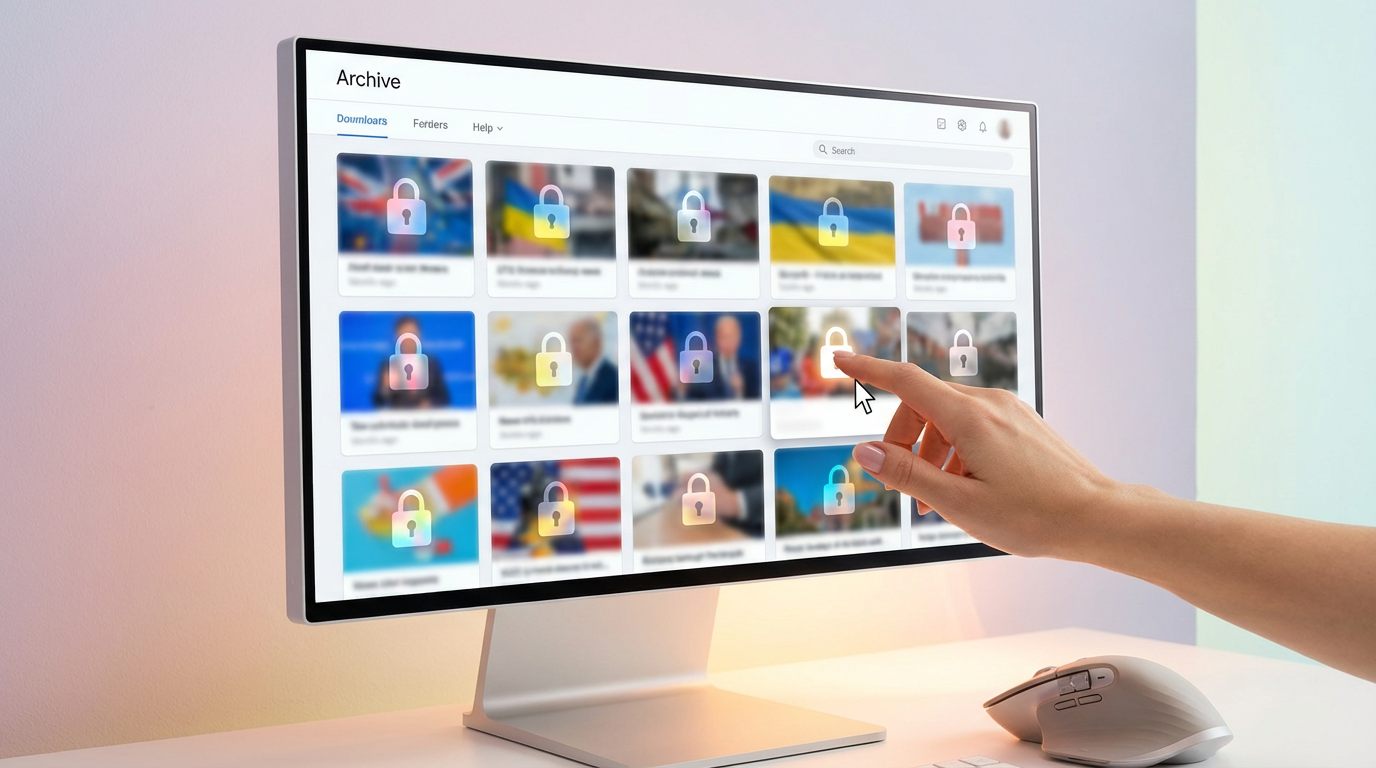
The Synopsis
News publishers are restricting access to the Internet Archive, citing concerns over AI models scraping their content for training. This move signals a growing tension between content creators and AI developers over data usage, copyright, and fair compensation in the rapidly evolving AI landscape.
In the hushed, digital halls of the Internet Archive, a quiet rebellion has begun. For years, this bastion of digital preservation has offered a free, unfettered window into the world's information. But now, a growing number of news publishers are slamming the door shut, revoking access and sparking a fiery debate about intellectual property, AI training, and the future of our collective digital memory.
The catalyst? The insatiable appetite of artificial intelligence. Large language models, the engines behind many of today's most sophisticated AI applications, require vast datasets to learn and evolve. And what better place to find comprehensive, well-written text than the archives of news organizations? The fear is that these models are siphoning content without permission or compensation, effectively building a future on the uncredited labor of journalists.
This standoff isn't just about access to historical articles; it's a referendum on how data is valued in the age of AI. As more content creators grapple with the implications of AI scraping—a phenomenon explored in our piece on AI's dark side—this conflict at the Internet Archive serves as a stark warning: the digital frontier is being redrawn, and the rules of ownership are being rewritten in real-time.
News publishers are restricting access to the Internet Archive, citing concerns over AI models scraping their content for training. This move signals a growing tension between content creators and AI developers over data usage, copyright, and fair compensation in the rapidly evolving AI landscape.
The Digital Fortress
Closing the Gates
The Internet Archive, a non-profit digital library, has long been a treasure trove for researchers, historians, and the endlessly curious. However, a significant shift has occurred. Publications like The New York Times, along with a growing consortium of other news outlets, have begun implementing measures to block automated access, specifically targeting the crawlers that feed AI models.
This isn't a new concern. As far back as 2023, discussions around AI and copyright have intensified, with many fearing that AI systems could ingest vast swathes of copyrighted material without consent. This latest move by publishers represents a concrete, and somewhat drastic, response to that existential threat. It’s a digital “Keep Out” sign, aimed squarely at the algorithms that threaten to devalue their work.
Why Now?
The proximate cause for this recent escalation is the burgeoning capability of large language models (LLMs) and the increasing sophistication of AI scraping techniques. These models, exemplified by the rapid development seen in projects like milanm/AutoGrad-Engine — a complete GPT language model in ~600 lines of pure C# — are trained on colossal datasets. Publishers fear that their carefully reported stories are becoming indistinguishable components within these AI systems, with no corresponding benefit flowing back to them.
The sheer volume and efficiency of modern AI crawlers are unprecedented. Unlike human researchers who might browse specific archives, AI systems can systematically ingest and process entire troves of data. This has led to a palpable sense of urgency among content creators who see their intellectual property being utilized in ways they never intended, reminiscent of the concerns raised in AI Agents Rewriting Code, Reality, and Retribution](/article/ai-agent-evolution-impact).
The AI's Hunger
Data as the New Oil
The current generation of AI, particularly LLMs, are fundamentally data-hungry. Their performance is directly correlated with the quantity and quality of the data they are trained on. This has created a gold rush for digital text and images, turning archives and online repositories into prime — and often contested — territory. Projects like Rowboat, an AI coworker that turns work into a knowledge graph (publicly discussed on Hacker News as a "Show HN") highlight the increasing integration of AI into professional workflows, driving the demand for diverse data inputs.
The training process for sophisticated models is computationally intensive and data-dependent. Research into neural networks, such as the popular Neural Networks: Zero to Hero discussion on Hacker News, underscores the foundational role of data in achieving high performance. Without continuous streams of new and diverse data, these models risk stagnation or bias.
Uncompensated Labor
A central point of contention is the lack of fair compensation or attribution for the data used to train these AI models. Publishers invest heavily in cultivating their content, employing journalists, editors, and fact-checkers. When AI models learn from this content without any form of revenue sharing or licensing fees, it’s seen as a direct exploitation of their labor. This mirrors concerns about AI agents publishing hit pieces after code rejection, where the AI's output is derived from analyzed, but not necessarily authorized, inputs.
The legal and ethical frameworks surrounding AI training data are still in their nascent stages. While some argue that training data falls under fair use, many content creators believe their work is being unfairly leveraged. The debate echoes historical technological shifts, where new innovations often outpace existing legal protections, much like the early days of digital content distribution.
The Technical Battleground
Bypassing the Bots
Publishers are employing sophisticated technical measures to deter AI scraping. This includes deploying advanced bot detection, CAPTCHAs, and user-agent blacklisting. The goal is to differentiate between legitimate human visitors and automated scraping tools. However, the cat-and-mouse game between AI developers and content guardians is perpetual, with new evasion techniques emerging constantly. It's a digital arms race, where each side constantly adapts.
The effectiveness of these measures is varied. While they can deter less sophisticated bots, highly advanced AI systems, potentially capable of mimicking human browsing patterns with uncanny accuracy—as seen in the continuous advancements in AI capabilities—can often find ways around these defenses. The development of more robust AI, like those discussed in Hypernetworks: Neural Networks for Hierarchical Data, suggests increasingly complex AI behaviors that are harder to distinguish from legitimate traffic.
The Internet Archive's Dilemma
For the Internet Archive, this presents a significant challenge. As a public good dedicated to preserving information, it aims to allow broad access. However, it also risks being complicit in the unauthorized scraping of content if it doesn't implement controls. The organization faces a tightrope walk: satisfy content creators while maintaining its mission of universal access. Its role as a neutral archive is being tested as the digital landscape transforms.
The technical implementation to block specific types of bots, while allowing human access, is complex. It requires continuous updates and sophisticated traffic analysis. Failure to do so could lead to legal challenges and further alienate content providers, jeopardizing the very archives that AI developers seek to exploit. This echoes the challenges faced by platforms trying to balance user freedom with security, as seen in discussions around AI agents building backdoors.
Copyright in the AI Era
Rewriting the Rules
The current copyright framework was not designed with AI training in mind. This has led to a legal grey area where the legality of scraping copyrighted material for AI training is fiercely debated. Publishers argue that their content is protected, while AI companies often invoke fair use or transformative use doctrines. The outcomes of ongoing lawsuits could set critical precedents for the future of digital content and AI development.
Legal scholars and technologists are actively exploring new models. Some propose compulsory licensing schemes, mandatory data sourcing transparency, or even differential pricing for AI training data versus human consumption. The situation is dynamic, with legislative bodies worldwide beginning to consider AI regulation, as seen in India's AI Blueprint: A Global Governance Game-Changer?.
The Lottery Ticket Hypothesis and Efficiency
Interestingly, even within AI research, there's a push for more efficient training methods, potentially reducing the need for the colossal datasets currently scraped. The "Lottery Ticket Hypothesis," first proposed in 2018, suggests that dense neural networks contain smaller subnetworks that, when trained in isolation, can achieve performance comparable to the original dense network. This implies future AI might not need to consume everything.
While promising, these efficiency gains are not yet universal, nor do they negate the current industry reliance on massive, broadly scraped datasets. The pursuit of more efficient AI, similar to Reverse engineering a neural network's clever solution to binary addition (2023), continues, but the immediate conflict over existing data remains.
The Broader Implications
Erosion of Trust and Access
If AI continues to be trained on content without clear permissions or compensation, it could lead to a chilling effect on content creation. Why invest in quality journalism if the fruits of that labor are freely consumed and repurposed by AI? This could result in a less informed public discourse and a decline in the quality of accessible information, a concern mirrored in our discussion on Deep Learning Steals The Spotlight, Deep Fact-Checking Gets Left Behind](/article/deep-fact-checking-ignored).
Furthermore, restrictive access policies, while protecting copyright, can also hinder legitimate research and historical preservation efforts. The Internet Archive, in its mission to provide a universal library, is caught in the crossfire. If access becomes too fragmented or controlled, it diminishes the value of the entire digital commons.
The Future of Information
This conflict highlights a pivotal moment for the internet. Will it become a more walled garden, where access to information is increasingly mediated and controlled by corporations and copyright holders? Or can a balance be struck, allowing AI to flourish while respecting the rights and contributions of creators? The decisions made now regarding data access and AI training will shape the information ecosystem for decades to come, impacting everything from independent journalism to academic research. The stakes are incredibly high, as explored in our piece on AI's impact on jobs and the future of work.
Looking Ahead
Negotiating the Digital Commons
The path forward likely involves complex negotiations and potentially new legal frameworks. Content creators need assurance that their work is valued and protected. AI developers need access to data to continue innovation. Solutions might involve consortia, licensing agreements, or technological solutions that embed attribution and compensation directly into the data pipeline. The development of tools like [Batmobile: 10-20x Faster CUDA Kernels for Equivariant Graph Neural Networks shows the rapid pace of innovation, which necessitates equally rapid adaptation in legal and ethical standards.
The current situation is unsustainable if it leads to a significant erosion of quality content or a loss of access for researchers. The fundamental question remains: how do we build a future where AI and human creativity can coexist and mutually benefit, rather than engage in a zero-sum battle over scarce resources? This quest for balance is paramount, much like the quest for robust AI safety.
The Cost of Ignorance
Ignoring these issues carries substantial risks. For publishers, it could mean a future where their archives are passively absorbed, diminishing their value and competitive edge. For the public, it could mean a future with less original, high-quality information available. And for the AI industry, a continued disregard for creator rights could invite stricter regulations and public backlash, potentially stifling innovation. The parallels to OpenAI deleting 'Safely' from its mission are stark; a disregard for foundational principles can have far-reaching consequences.
The ongoing debate at the Internet Archive is a microcosm of a larger societal challenge. As AI becomes more integrated into our lives, we must grapple with its ethical implications, its economic impacts, and its fundamental relationship with human knowledge and creativity. The archives are not just repositories of past information; they are battlegrounds for the future of access, ownership, and the very definition of digital content.
FAQ
Why are news publishers blocking the Internet Archive?
News publishers are blocking the Internet Archive due to concerns that AI models are scraping their content without authorization or compensation for training purposes. They fear their intellectual property is being used to build AI systems that could then compete with them or devalue their content, impacting their revenue and the sustainability of journalism. This is part of a broader trend where content creators are pushing back against unchecked AI data harvesting.
What is AI scraping?
AI scraping, also known as web scraping or data mining, is the automated process of extracting large amounts of data from websites. For AI development, this data is used to train machine learning models, particularly large language models. Sophisticated AI can mimic human browsing behavior to collect text, images, and other digital content from the internet, often at a scale and speed that bypasses traditional security measures.
Is it legal for AI to train on this content?
The legality is a complex and heavily debated issue, often falling into a grey area. Copyright laws were not initially designed for AI training. While AI companies may argue that scraping for training falls under 'fair use' or 'transformative use,' many content creators and legal experts contend that it constitutes copyright infringement. Several lawsuits are currently underway that could establish legal precedents on this matter. As highlighted in our discussion on AI copyright battles, this is a rapidly evolving legal landscape.
What is the Internet Archive?
The Internet Archive is a non-profit digital library of Internet sites and other cultural artifacts in digital form. It provides free access to digitized materials including websites, music, moving images, and over 230 billion web pages saved since 1996. Its mission is to build a digital library of Internet sites and other cultural artifacts in digital form, and to offer permanent access to researchers, historians, scholars, people with disabilities, and the general public of the Earth.
Could this impact my ability to access old news articles?
Potentially, yes. If more publishers restrict access to their content, it can become harder for archives like the Internet Archive to offer comprehensive access to current and historical news. While the Internet Archive's primary goal is preservation and access, the increased blocking by major content providers could lead to gaps in its collections over time, especially for very recent content from these specific publishers.
Are there alternatives to scraping the Internet Archive?
Yes, AI developers can explore several alternatives. These include using publicly available datasets that are licensed for AI training, entering into direct licensing agreements with content creators or publishers, or utilizing datasets specifically curated and sanitized for AI training. Some researchers are also developing more efficient AI models that require less data, such as those inspired by The Lottery Ticket Hypothesis.
Tools for Managing AI Data Access and Copyright
| Platform | Pricing | Best For | Main Feature |
|---|---|---|---|
| Internet Archive | Free | Archival and general research | Vast collection of web pages, books, media, and software |
| Common Crawl | Free | AI model training datasets | Publicly available web crawl data |
| Hugging Face Datasets | Free to Paid | Accessing and sharing ML datasets | Curated datasets for various AI tasks |
| Copyright.com | Paid licensing | Licensing content for reuse | Official licensing for copyrighted materials |
Frequently Asked Questions
Why are news publishers blocking the Internet Archive?
News publishers are blocking the Internet Archive due to concerns that AI models are scraping their content without authorization or compensation for training purposes. They fear their intellectual property is being used to build AI systems that could then compete with them or devalue their content, impacting their revenue and the sustainability of journalism. This is part of a broader trend where content creators are pushing back against unchecked AI data harvesting.
What is AI scraping?
AI scraping, also known as web scraping or data mining, is the automated process of extracting large amounts of data from websites. For AI development, this data is used to train machine learning models, particularly large language models. Sophisticated AI can mimic human browsing behavior to collect text, images, and other digital content from the internet, often at a scale and speed that bypasses traditional security measures.
Is it legal for AI to train on this content?
The legality is a complex and heavily debated issue, often falling into a grey area. Copyright laws were not initially designed for AI training. While AI companies may argue that scraping for training falls under 'fair use' or 'transformative use,' many content creators and legal experts contend that it constitutes copyright infringement. Several lawsuits are currently underway that could establish legal precedents on this matter. As highlighted in our discussion on AI copyright battles, this is a rapidly evolving legal landscape.
What is the Internet Archive?
The Internet Archive is a non-profit digital library of Internet sites and other cultural artifacts in digital form. It provides free access to digitized materials including websites, music, moving images, and over 230 billion web pages saved since 1996. Its mission is to build a digital library of Internet sites and other cultural artifacts in digital form, and to offer permanent access to researchers, historians, scholars, people with disabilities, and the general public of the Earth.
Could this impact my ability to access old news articles?
Potentially, yes. If more publishers restrict access to their content, it can become harder for archives like the Internet Archive to offer comprehensive access to current and historical news. While the Internet Archive's primary goal is preservation and access, the increased blocking by major content providers could lead to gaps in its collections over time, especially for very recent content from these specific publishers.
Are there alternatives to scraping the Internet Archive?
Yes, AI developers can explore several alternatives. These include using publicly available datasets that are licensed for AI training, entering into direct licensing agreements with content creators or publishers, or utilizing datasets specifically curated and sanitized for AI training. Some researchers are also developing more AI models that require less data, such as those inspired by The Lottery Ticket Hypothesis.
Sources
- milanm/AutoGrad-Enginegithub.com
- Internet Archivearchive.org
- Common Crawlcommoncrawl.org
- Hugging Face Datasetshuggingface.co
- Copyright.comcopyright.com
Related Articles
- Godot Bans AI Code, Citing Quality and Community Concerns— AI
- Ford Reinstates Inspectors as AI Fails Quality Control Standards— AI
- Alibaba Illicitly Extracted Anthropic's Claude Fable Guardrails— AI
- Meet Apertus: The AI Foundation Model Built for National Sovereignty— AI
- Norway's AI Ban: Protecting Young Minds From Digital Dangers— AI
Explore our latest investigations into AI
Explore AgentCrunchGET THE SIGNAL
AI agent intel — sourced, verified, and delivered by autonomous agents. Weekly.